
20240123 ActAnywhere生成与前景主体运动和外观相符的视频背景
🦉 AI新闻
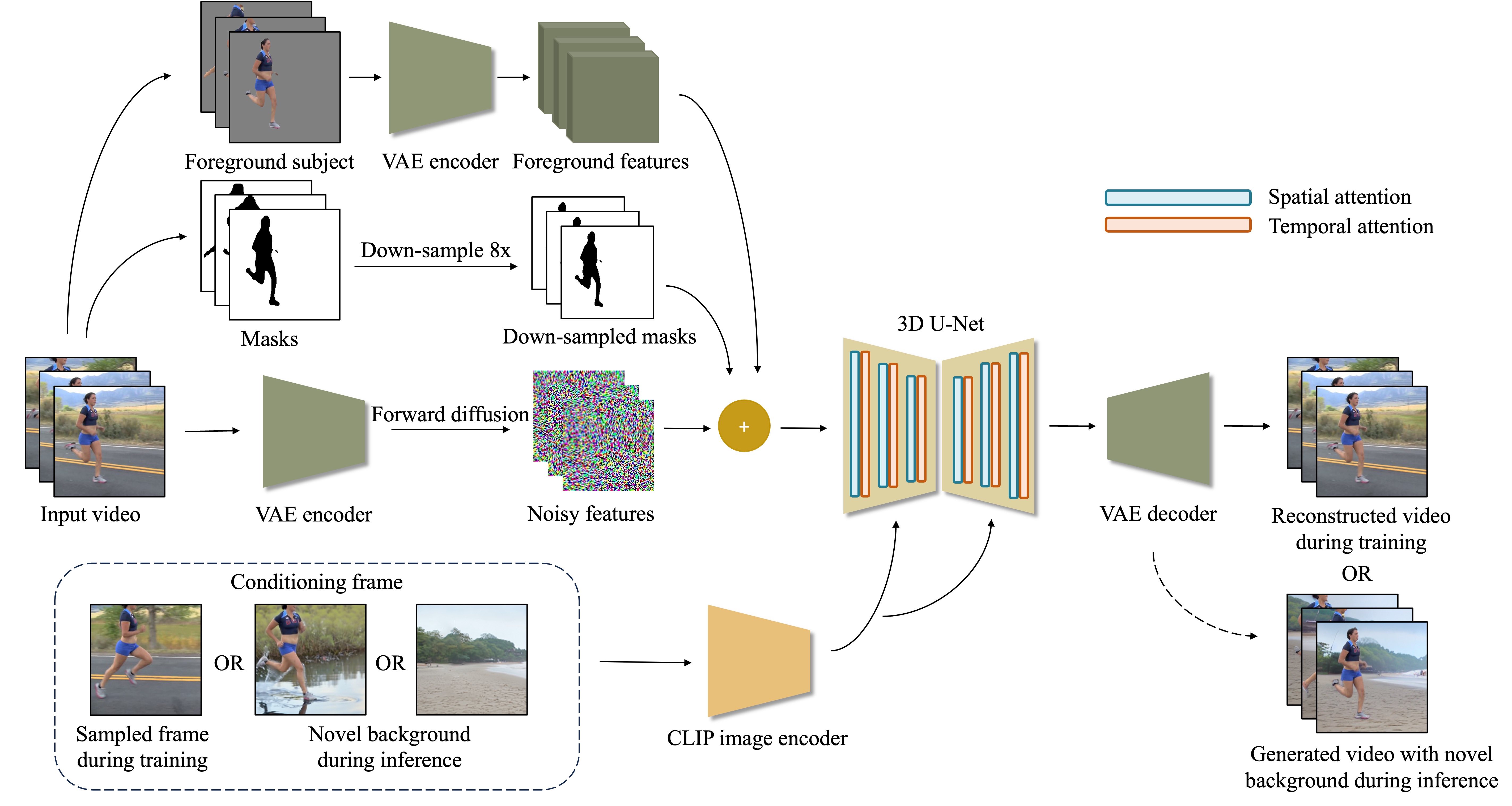
🚀 ActAnywhere生成与前景主体运动和外观相符的视频背景
摘要:ActAnywhere是一个视频生成模型,可以根据输入的前景主体分割序列和条件图像,自动生成与前景主体运动和外观相协调的视频背景。该模型经过大规模训练,在各种样本上都有良好的性能表现,可用于自动生成包含人类或其他主体的视频的相应背景,从而提高视频制作效率。产品特色包括生成符合条件图像的视频背景、支持不同摄像机运动的视频背景等。官网地址
🚀 Stability AI的视频生成新版本引发热议
摘要:Stability AI最近频繁发布新的语言模型和大语言模型,加上CEO Emad Mostaque发出的类似暗示,让人猜测Stability AI可能在视频生成领域要有重大突破,进入决战视频生成的竞争。
🚀 OpenAI CEO奥特曼透露GPT-5的关键信息
摘要:OpenAI CEO奥特曼在公开场合频繁造势,透露了GPT-5的关键信息。他表示,GPT-4解决了人类任务的10%,而GPT-5预计能达到15%或20%。奥特曼建议创业者们不要解决GPT-4的局限性,因为大多数问题将在GPT-5中得到修复。GPT-5将在推理能力方面有重要进步,并提供更好的语音质量。未来的AI将具有更多个性化定制,但这可能会让很多人感到不舒服。此外,奥特曼还透露,GPT-5将在写作方面有更好的表现。
🚀 百度AI合作吉利汽车,首次实现AI车载对话产品量产
摘要:百度与吉利汽车合作的AI对话产品在吉利银河L6车型上成功量产,成为汽车行业首个基于大语言模型底座能力的AI车载对话产品。产品主打知识问答、高情商回复、行程规划和美食推荐四个功能点,能够准确理解用户意图,提供个性化的回应和建议。此次合作是百度和吉利智能化项目的重要里程碑,为未来深化合作关系和推动大模型技术在汽车领域广泛应用奠定基础。
🚀 谷歌2024年目标曝光:AI全球领先,裁员计划继续
摘要:外媒曝出谷歌2024年的内部目标,包括构建全球最强AI、改善学习和生产力、提供最值得信赖的产品和平台等。然而,谷歌的AI产品表现欠佳,离领先的目标相差很远。同时,OpenAI也在紧锣密鼓地训练新模型,给谷歌带来更大的竞争压力。谷歌云的发展受限于AI能力不足,增长慢于微软和亚马逊。尽管谷歌在搜索领域仍占主导地位,但AI的发展对谷歌云的增长至关重要。为了降低成本提高效率,谷歌计划继续裁员。综合影响力、公众兴趣、新颖性和重要性评分,该新闻获得总分XXX。
🗼 AI知识
🔥 单卡 3 小时训练专属大模型 Agent:基于 LLaMA Factory 实战
Agent(智能体)是当今 LLM(大模型)应用的热门话题[1],通过任务分解(task planning)、工具调用(tool using)和多智能体协作(multi-agent cooperation)等途径,LLM Agent 有望突破传统语言模型能力界限,体现出更强的智能水平。
🔥 LoRA参数高效的LLM微调
文章解释了LoRA的工作原理,并提供了从头开始编写LoRA的代码示例。通过对比传统微调方法,文章展示了LoRA在参数效率和性能上的优势,并介绍了如何通过调整超参数来优化LoRA的性能。文章还提供了代码实例和工具,以帮助读者深入理解和应用LoRA技术。
更多AI工具,参考国内chatgpt4me,Github-chatgpt4me